Reciclar o reutilizar código HTML con Javascript Vanilla
Utilizar un documento HTML para copiar lo que hay en el body en otros documentos HTML nos facilita el hecho de repetir las siguientes acciones: borrar, editar, copiar y pegar código muchas veces. Por eso con este método vamos a reutilizar código HTML con Javascript puro y nos ayudará a resolver el problema inicial.
Este método nos ayuda a evitar editar una misma parte de código que tenemos en distintos archivos HTML utilizando un modelo. Por ejemplo, en cualquier página que visitamos vemos que el encabezado (header) se encuentra, generalmente, en todos las páginas del sitio web, al igual que el pie de página (footer). Por eso, cuando uno está desarrollando su sitio web sin ningún CMS (como WordPress) se vuelve tedioso editar mismas partes de código en todos los archivos que lo necesitemos.
Siguiendo el caso de ejemplo, vamos a enseñarles cómo colocar contenido que queramos tener en distintos archivos HTML de una manera sencilla, utilizando Javascript Vanilla (sin librerías externas), con código y su explicación. Cabe aclarar que este método no es excepcionalmente único para cumplir con el objetivo, ya sea con o sin librerías. Si se investiga se puede encontrar con distintas formas de lograr lo mismo, dependiendo de lo que busque el desarrollador.
Comenzamos con el método
En la siguiente imagen vemos los archivos con los que vamos a estar trabajando. Ubicados en la carpeta raíz del proyecto para que no sea más cómodo manejarlos, pero se pueden colocar donde usted quiera. Es necesario mencionar que se recomienda utilizar la ruta de los enlaces de la forma relativa a la raíz (son las que comienzan con /). Para saber más sobre los tipos de rutas que existen haga click aquí.
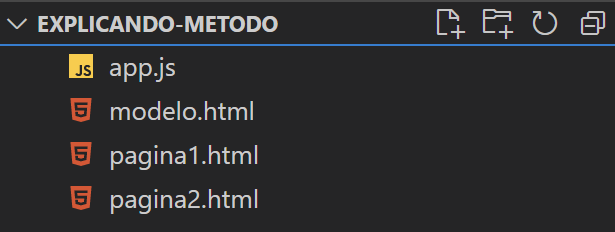
En el que modelo.html es el archivo en el que vamos a contener lo que queremos tener en los archivos pagina1.html y pagina2.html.
Continuando, en el archivo modelo.html vamos a escribir la parte de código que queremos que se use de modelo, dentro del body, por lo tanto, antes debemos hacer la estructura básica de un documento HTML:
<!DOCTYPE html>
<html lang="es">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Modelo</title>
</head>
<body>
</body>
</html>Código 1. Archivo modelo.html
Y luego dentro del body agregamos lo que queremos usar de modelo, en nuestro caso de ejemplo lo siguiente:
<body>
<header>
<h1>TechWiz</h1>
<nav>
<ul>
<li><a href="#">Inicio</a></li>
<li><a href="#">Categorías</a></li>
<li><a href="#">Acerca de</a></li>
<li><a href="#">Contacto</a></li>
</ul>
</nav>
</header>
</body>Código 2. Archivo modelo.html
Ahora que tenemos el modelo lo que sigue es aplicarlo con Javascript en los archivos pagina.html y pagina2.html. Vamos a estar trabajando con uno de los dos ya que en los dos se aplica el mismo código. Teniendo la estructura básica al igual que en el código 1, lo que sigue es agregar un etiqueta div en el body en la parte deseada para pegar el modelo creado en el archivo modelo.html, aplicando una clase descriptiva al div. De la siguiente manera:
<!DOCTYPE html>
<html lang="es">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Pagina 1</title>
</head>
<body>
<div class="pegar-modelo"></div>
<p>Contenido pagina 1</p>
<!-- mas código html -->
</body>
</html>Código 3. Archivo pagina1.html
Y luego agregar la conexión con el archivo javascript app.js:
<body>
<div class="pegar-modelo"></div>
<p>Contenido pagina 1</p>
<!-- mas código html -->
<script src="/app.js"></script>
</body>Código 4. Archivo pagina1.html
Ahora sigue trabajar con javascript en el archivo app.js, en el que vamos a empezar haciendo una llamada fetch al archivo que usamos de modelo (modelo.html), de la siguiente manera:
fetch("/modelo.html")
.then(response => response.text())
.then(data => {
console.log(data);
})
.catch(err => console.log(err));Código 5. Archivo app.js
Hacemos una llamada fetch al archivo el cual usamos como modelo. Este se puede encontrar en cualquier ruta del proyecto. Por ejemplo, si está en una carpeta “modelos”, la ruta que debemos colocar en el fetch sería “/modelos/modelo.html”. Mostramos en consola data para verificar que todo funcione correctamente, debería verse en consola el texto de modelo.html en tipo string.
Como se puede ver usamos rutas relativas a la raíz. Si usted para visualizar el HTML en el navegador lo abre directamente haciendo click en el archivo (en su ruta del navegador ve algo como file:///C:/Users/usuario/ Documents/proyecto/pagina1.html) y no con un visualizador en tiempo real con una extensión como Live Server, no va poder visualizar el modelo, por lo que le recomendamos utilizar esa extensión. Al desplegar tu proyecto con GitHub Pages o Netlify, no va haber problemas al utilizar estar rutas relativas a la raíz.
A continuación hacemos una instancia de DOMParser, que nos sirve para convertir un string a un documento HTML virtual utilizando su metodo parseFromString, que toma dos argumentos, el primero es la cadena de texto que queremos parsear y el segundo el tipo de documento al que queremos convertir, en nuestro caso “text/html”, de la siguiente manera:
fetch("/modelo.html")
.then(response => response.text())
.then(data => {
console.log(data);
const parser = new DOMParser();
const htmlDoc = parser.parseFromString(data, "text/html");
})
.catch(err => console.log(err));Código 6. Archivo app.js
Ahora que tenemos el documento modelo.html de manera virtual, lo que sigue es obtener la parte deseada de modelo.html, en este caso, lo que se encuentra dentro de body, por lo que utilizamos htmlDoc.querySelector para obtener el elemento deseado, y a su vez utilizamos innerHTML en el elemento para obtener esa parte en string. Aqui el codigo:
fetch("/modelo.html")
.then(response => response.text())
.then(data => {
console.log(data);
const parser = new DOMParser();
const htmlDoc = parser.parseFromString(data, "text/html");
const content = htmlDoc.querySelector("body").innerHTML;
})
.catch(err => console.log(err));Código 7. Archivo app.js
Lo que sigue es pegar el código modelo en el elemento que asignamos para esto en pagina1.html. Utilizamos document.querySelector para obtener el elemento del documento pagina1.html “pegar-modelo” y volvemos a usar innerHTML en este elemento, pero esta vez asignándole un valor, que será content:
fetch("/modelo.html")
.then(response => response.text())
.then(data => {
// console.log(data);
const parser = new DOMParser();
const htmlDoc = parser.parseFromString(data, "text/html");
const content = htmlDoc.querySelector("body").innerHTML;
const elementPaste = document.querySelector(".pegar-modelo");
elementPaste.innerHTML = content;
})
.catch(err => console.log(err));Código 8. Archivo app.js
De esta manera, obtenemos que en pagina1.html, en el div con clase “pegar-modelo”, dispone con el header creado en modelo.html.
Finalmente, para cumplir con el objetivo, a los archivos HTML en los que queremos utilizar el modelo (en nuestro caso de ejemplo pagina1.html y pagina2.html), lo que sigue es aplicar la el siguiente elemento en la parte deseada (en este caso al ser un header siempre va al principio del body):
<div class="pegar-modelo"></div>Y vincularlo con el script que creamos:
<script src="/app.js"></script>Cabe mencionar que el script debe ir al final del body o aplicar otras técnicas para esperar a que cargue el documento y luego el script.
De esta manera, así quedaría el archivo pagina2.html:
<!DOCTYPE html>
<html lang="es">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Pagina 2</title>
</head>
<body>
<div class="pegar-modelo"></div>
<p>
Otro contenido distinto
</p>
<!-- mas código html -->
<script src="/app.js"></script>
</body>
</html>Codigo 9. Archivo pagina2.html
Extra: evitar que se indexe el modelo
Al momento de querer hacer nuestro sitio web algo profesional, nos referimos a desplegarlo en un dominio y hosting (puedes saber más sobre lo que debes saber al momento de crear un sitio web haciendo click aquí) y querer tener un trafico en nuestra web, recomendamos aplicar la siguiente etiqueta meta en el head de los archivos que usemos como modelo:
<meta name="robots" content="noindex, follow"/>Simplemente nos sirve para que Google y otros buscadores no indexen (no aparezca en las búsquedas) estos documentos HTML, pero que si reconozca los enlaces que se encuentran dentro de él.
Conclusión
En este artículo, hemos explorado un método sencillo para copiar contenido del cuerpo de un archivo HTML a otros archivos HTML utilizando JavaScript Vanilla. Este enfoque nos permite evitar la tediosa tarea de editar las mismas partes de código en múltiples archivos, como el encabezado y el pie de página, presentes en la mayoría de los sitios web.
Es importante destacar que cada proyecto puede presentar diferencias en cuanto al nombre de las clases, el contenido del modelo y otros aspectos. Sin embargo, el método proporcionado aquí sirve como un punto de partida para simplificar la reutilización de código y facilitar la actualización de contenido en varios archivos HTML.
Al utilizar JavaScript Vanilla, nos liberamos de la dependencia de librerías externas y podemos adaptar el código a las necesidades específicas de nuestro proyecto. Además, es importante recordar que existen otras formas de lograr este objetivo, y los desarrolladores pueden explorar diferentes enfoques según sus preferencias y requerimientos.
En resumen, al aplicar el método presentado en este artículo, podemos ahorrar tiempo y esfuerzo al evitar la duplicación de código y facilitar la gestión de contenido en varios archivos HTML. Aprovechando las ventajas de JavaScript Vanilla, podemos personalizar el proceso según las particularidades de nuestros proyectos y lograr un flujo de trabajo más eficiente y mantenible.